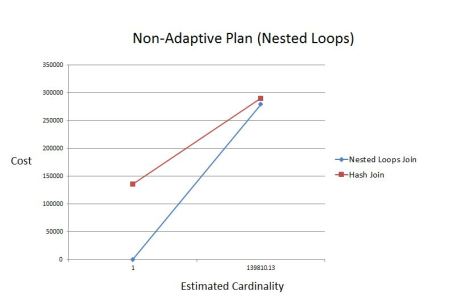
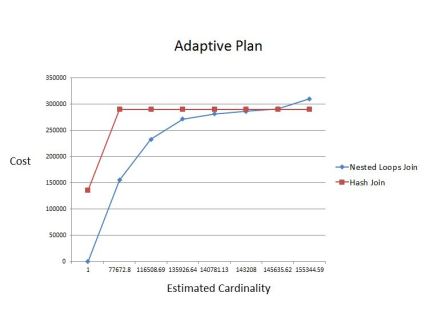
Adaptive execution plans is a new Oracle 12c feature. I consider it one of the most important ones.
Oracle 12c would pick the join method based on the actual number of rows retrieved during the first execution of the query.
There are a few great papers about this topic:
Here is the Oracle’s white paper and here is Kerry Osborbe’s Hostsos 2013 presentation. There is even a video.
Every time a new feature that fundamentally changes the way Oracle works is introduced, we should ask ourselves what is the cost, in terms of CPU or other resources, used by that feature.
For me, the cost is an issue only when the feature does not change the join type that was initially chosen.
If the feature causes a change of join type, then the benefits of it would be huge, so it is not worth worrying about the cost.
I’ll measure the elapsed times / looking at internals is hard… ![]() / of a query with and without adaptive execution plans and then run a paired t-test to see if there is a statistically significant difference. I’ll use OPTIMIZER_ADAPTIVE_REPORTING_ONLY to turn on and off the feature and I’ll do my best to get rid of any bias in this test.
/ of a query with and without adaptive execution plans and then run a paired t-test to see if there is a statistically significant difference. I’ll use OPTIMIZER_ADAPTIVE_REPORTING_ONLY to turn on and off the feature and I’ll do my best to get rid of any bias in this test.
First, let’s see what happened when we have a query that uses Hash Join. The table/view set up scripts is here. The test procedure is here. I get the end-result using this simple query:
select avg(r), avg(a) , STATS_T_TEST_PAIRED (R,A) FROM track_v
For this case, we get avg(r) = 450.6991608 , avg(a) = 451.5071414 , STATS_T_TEST_PAIRED (R,A) /p/ = 0.48716074654373898
This means that for 10K runs, we are nowhere near statistical significance (p< 0.05). Things were not different for 100K runs:
avg(r) = 336.78178535 , avg(a) = 336.67725615 , STATS_T_TEST_PAIRED (R,A) /p/ = 0.82934281196842896
Therefore, the adaptive execution plan feature does not add any meaningful cost when Hash Joins are used.
Let’s see the behavior for a query the uses nested loops. The table/view set up scripts are here. The test procedure is here. I ran 100K iterations, and this is what I got:
select avg(r), avg(a) , STATS_T_TEST_PAIRED (R,A) FROM track_v
For this case, we get avg(r) = 15.31589686 , avg(a) = 15.11440871 , STATS_T_TEST_PAIRED (R,A) /p/ = 0.015795071536522352
Very interesting result - using adaptive execution plans is slightly faster even when no runtime change of join type is happening. The result seems to have statistical significance…
I then run 500K iterations and I got the even stronger result:
avg(r) = 20.4530 , avg(a) = 19.982423, STATS_T_TEST_PAIRED (R,A) /p/ = 0.00000320884674226468
The averages went up probably because there was some load on the box, but the statistical significance of the difference is out of the question.
So, it appears that the cost of adaptive execution plans is actually negative when it comes to nested loops (NL).
Overall, adaptive execution plans could bring huge benefits without any cost. I cannot think of a scenario where we should turn them off…